
zvr@aueb.gr)
This is an abridged version of a much lengthier report.
More information is available from the author.
This report is an effort to comprehensively present the available approaches to the issue of dealing Greek characters in computer environments. Following a description of the basic problem, existing solutions for a number of different platforms are charted in separate sections. In addition to the current state of affairs, each section also includes a brief historical review of the approaches taken.
While using Greek characters on a computer is a seemingly simple process, a closer analysis reveals that it entails the issues of storage, input, display and hardcopy output. All these appear in this paper, together with general information on available solutions. The ensu- ing platform-specific discussion presents the differences between them, as well as some particular points of interest.
Of the above mentioned issues, the approach to storing Greek characters in a computer presents the most essential problem, and yet the easiest to solve. Fortunately, the characters involved are not too many. If one focuses only in the modern Greek monotonic language, there are only 69 distinct letters: 24 upper case ones, 24 lower case, 1 lower case final sigma, 7 accented upper case and 7 lower case vowels, 2 upper case and 2 lower case vowels with diaeresis and 2 lower case vowels with accents and diaeresis. This is quite a small number com- pared, say, with the number of Chinese or Japanese letterforms. Since there are less than 96 slots available -- this number is arrived at after subtraction of the 32 control character slots from the 128 total number of characters represented with 7 bits in the standard American Standard Code for Information Interchange (ASCII) encoding -- one might expect that they could be represented in 7-bit quantities. However, since almost all recent computing systems usually deal with 8-bit bytes, the almost universal approach is to place the Greek characters in the upper half of the 256-place table. Thus, we arrive at a table containing the usual ASCII character set in the lower half and the Greek characters in the upper half. In future reference, we will call Latin the characters with code numbers ranging from 32 to 127 (the usual ASCII set), and Greek those with character codes from 128 onwards. Due to the fact that the Greek characters have their Most Significant Bit (MSB) set, they are often also called 8-bit characters.
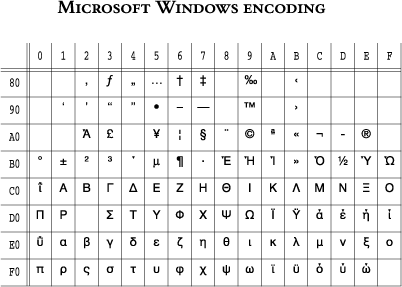
Obviously, there are countless ways of allocating the 69 Greek characters in the 128 upper places of the 256-place character table and, as Murphy's Law dictates, several of these find their way in widespread use. There is actually only one official standard, created by the Hellenic Organization for Standardization (ELOT) and approved by the International Stand- ards Organization (ISO), as ISO 8859-7. It is also known by its national code as ELOT-928. The standard, the seventh in the series of ISO 8859 adheres to the general standards, which specify that the first 32 places of both halves of the character table should be reserved for control characters.
The standard in question is shown in the above table and has the following characteristics:
It should be noted that, as in all ASCII characters, to get a lower case letter from an upper case one or vice versa, one simply needs to respectively set or clear a single bit. This is true, however, only for letters without diacritical signs. Letters with accents or diaereses, as well as the final sigma, do not come under this rule.
Once the character codes for machine representation are decided, the problem to deal with is that of actually entering these characters in the computer. Since there are no keyboards with 256 different keys for as many characters, standard keys are used in a particular manner for this purpose. The method applied on all platforms is a toggling mechanism, which alternates between the two keyboard modes: the Latin and the Greek. When the keyboard is in Latin mode and the user presses the A key, the Latin character a is generated, while, when in Greek mode, the character code for the Greek character alpha is generated. This is achieved by means of a keyboard driver, a program which constantly monitors the keyboard and generates the appropriate characters. As it can be easily understood, this program must be the first to receive and intercept any keyboard activity.
The correspondence between the keys pressed and the Greek characters generated is based on the standard Greek typewriter layout. To produce all the Greek characters in alphabetic order, the user has to type the Latin keys abgdezhuiklmnjoprstyfxcv. The final sigma is accessed by typing the lower case w. The way to produce letters with diacritics (accents and/or diaereses), is also based on the standard Greek typewriter layout: one must first type the diacritic key and then the vowel. Diacritics are usually attained through the semicolon key by itself for the accent and the same key with simultaneous depression of the shift key for the diaeresis -- the single/double quote key may also used in the same manner. The toggling mechanism is completely platform-dependent and, in some cases, program-dependent but it usually involves the depression of some combination of keys.
Having devised a way of entering the Greek characters in the computer, the next step is towards actually viewing them on the display screen. The following discussion will concentrate only on pixel-based displays and omit other technologies, such as the line-drawing terminals, since there is no access to information on such technological approaches of hardware.
Those familiar with the early stages in the field may remember computer screens equipped with a switch that toggled the Latin and Greek characters displayed on the screen. In these models, the display could be in one mode only and no simultaneity of the two alphabets was possible. Incidentally, these displays were not only for terminals, but also for consoles on personal computers of the time -- running CP/M, for example.
Next came the character-based displays, which were only capable of displaying characters contained in their character-generating chip, usually stored in an Erasable Programmable Read-Only Memory (EPROM). Thus, if the user wanted to view Greek characters on the screen, a special chip had to be installed. The original Digital Equipment Corp. VT102 is a display of this kind, as are the Hercules and CGA cards for the IBM PCs and their compatibles.
The next step was the character-based screens allowing downloading of character forms from software. The user could download one to four character sets of 127 characters each, and then switch between them with special commands. Alternatively, he could download, overwrite and use a single 256-place table. The Digital Equipment Corp. VT220 is a display of this kind, as are the EGA and VGA cards for the IBM PCs and their compatibles.
Eventually, the bitmap displays emerged, where all information is based on bitmap graphics. Since all characters displayed on such screens are in graphic form, there is no essential difficulty in producing Greek characters. Examples of bitmap displays are the X Window System terminals, the Apple Macintosh, as well as the IBM PCs and their compatibles running Microsoft Windows.
The next stage in processing Greek characters is the ability to produce them in hardcopy, i.e. through a printer. This problem has about as many parameters as the differences between the various printer technologies.
Dot-matrix printers are capable of producing characters contained in their character generating chip only, much like the kind of character-based displays mentioned above. The ability to generate Greek characters is contingent solely upon the existence of this special chip. In view of the variety of available EPROMs providing the most widespread encodings, one should ensure that there is encoding compatibility between the host and the printer.
Laser printers, on the other hand, operate much like the bitmap displays. Instead of storing the character shapes in an EPROM, they allow the downloading of glyph descriptions from software. In this case, Greek characters are treated exactly the same as the Latin ones. In recent years, there has been a proliferation of such downloadable fonts with Greek characters, mainly for printers which operate by means of the PostScript programming language.
Although a variety of different hardware and software items come under the designation of Unix, they will be discussed as an entity in this section. Greek computer science students in Greece and abroad have developed the majority of numerous methods for the use of Greek characters in this platform. The following is based on the method developed by the author and others in the National Technical University of Athens.
As there were no reasons for deviation from it, the ELOT/ISO standard was adopted for the encoding of Greek characters. Implementing the input of Greek characters presented many more difficulties. Depending on the terminal used, there are two different approaches:
Once the input mechanism is operative, one encounters many more problems than ever imagined. Until recently, the number of programs capable of dealing with Greek characters was surprisingly small. Under these circumstances and in cases when the means, i.e., the actual source code, was accessible, one had to fix a multitude of programs. The effort at the National Technical University of Athens was based on the 4.3 BSD code, parts of which were ported to many different architectures. Of these programs, the easiest to fix were the ones that completely ignored the eighth bit of each character. The hardest work was fixing programs actually using this eighth bit for their own purposes (csh and vi are examples of this kind of programs). However, in order to provide a fully functional system, too many components need to be changed, such as the kernel so that Greek characters may appear in filenames, etc.
An examination of the use of Greek characters in computing systems in general and in the Unix system in particular, shows that the majority of related applications (from word processing to desktop publishing) serve document processing purposes. In their overwhelming majority, users of Unix systems employ document processing programs such as troff (or one of its many variants) and TeX. Both these programs include a rudimentary way of producing Greek characters to cater to their users needs for mathematical notation. One can, therefore, devise a rather simple approach of transforming the input in mathematical Greek so that the desired result may be attained. As a matter of fact, there is a very large number of small filters (utilized on anything, from sed scripts to Fortran programs), which perform this function. It seems that every user of these programs has, at some point or another, produced one. The actual modification of these programs to handle Greek text is much more difficult, yet unavoidable, since mathematical Greek is simply not an acceptable solution. A document processing system must also accomplish much more than just produce the characters syllabification being one of the most difficult requirements. Both these programs now have variants that can accept Greek characters and, within some limitations, do a more-or-less satisfactory formatting job. Despite the ever increasing number of document processing programs, the need for an approach tailored to the Greek language remains to be developed.
Another area of primary importance, where the handling of Greek characters leaves a lot to be desired, is the communication between hosts. The standard for electronic mail messages, developed years ago, but still valid, actually specifies that the messages can contain only 7-bit characters. Needless to say, with the advent of MIME, this is no longer a problem, since it is now possible to communicate with Greek text employing a standards-based solution.
Various techniques of encapsulating the Greek characters in 7-bit ASCII characters have been proposed in the past, but they are all based on the premise that the converting software is universally available and that all users agree on its use. Among the very large number of mappings of Greek characters on Latin ones, there are three distinct variants:
For all the above reasons, there is no Unix system to date capable of dealing with Greek characters as it does with Latin ones. However, as the idea of internationalization acquires more supporters and is further promoted through the various standards in the last few years, suppliers of Unix systems are moving towards providing increased support for national languages. Although some programs are now capable of using these resources, no complete codification for the Greek environment has yet been produced. This is an area where a lot more needs to be done, especially in light of suppliers current proprietary methods and formats which render work done in a specific machine incompatible with any other one.
The Apple Macintosh platform is particularly interesting because it was, for a long time, the one which provided the best support for Greek characters since its initial introduction in Greece. Although this platform offers many capabilities for Greek characters (e.g., Greek characters may be used in all the machine resources) it also presents some peculiarities.
The encoding used for Greek characters is a special one, probably devised locally by the company that imports the majority of Apple machines in Greece. Some of its characteristics and versions of the system software have even changed with time without, however, creating major incompatibilities.

The single most important characteristic is that, using the ordinary keyboard driver named «regular», the Greek characters that share the same glyphs with Latin ones, like A, B, E, H, K etc., are replaced by them. For example, when the user types the word Auhna (Athens) in Greek mode, the first letter will be the Latin capital A (decimal 65 in ASCII). As one can imagine, programs that manipulate text data (even for simple sorting, not to mention spelling checkers) must have special functions for reading the characters correctly.
The fonts used in the past by Apple Macintosh followed this transformation approach, and did not include a separate glyph for Greek characters which are the same as the Latin ones. Beginning with Apple system software version 6.0.4, the fonts include these glyphs in two dif- ferent positions, one for the Latin characters and one for the Greek ones. Despite this change, the «regular» keyboard driver still substitutes the Greek common characters with their equivalent Latin ones. There was a special keyboard driver named «separate», which produced the correct codes, but it disappeared with the advent of Apple system software version 7.
Another point of interest is that A/UX, which is Apple's Unix-like operating system that runs on the same platform, uses the ISO/ELOT standard for its Greek characters. Conversions between the different character sets are done automatically by cutting and pasting.
The keyboard driver allows toggling of the keyboard state between Latin and Greek by the simultaneous depression of the Command and Space keys. This method is used in Apple system software version 7 for rotation through all installed keyboard drivers.
Also worth mentioning is the unique capability of the Macintosh platform in dealing with other forms of the Greek language, like polytonic Greek, which contains more diacritical signs than the few used in modern monotonic and, therefore, requires more glyphs. The encoding for the representation of these characters occupies both halves of the character table, thus, precluding that of Latin characters. In order to use this encoding, one must choose another keyboard driver, appropriately called «polytonic.» Unfortunately, the user can only install this driver during the initial installation of Apple system software version 7.
The IBM PC must be discussed as a somewhat special platform, in view of its ubiquitous presence in all areas of computerized systems and the multiplicity of solutions it lends to the problem of handling Greek characters.
For the display of characters, the simplest solution has been adopted; namely, sending the character, whose code was stored, to be shown on the screen. For PCs that use the Hercules or the CGA graphics card, the only solution lies in their hardware. The characters displayed on the screen, when in text mode, are stored in a character generator (an EPROM chip), so the availability of Greek characters is contingent upon the presence of this unit. It should be noted that all PCs sold in Greece contain this chip. For machines equipped with EGA or VGA cards, the characters can be downloaded via software and there is no need for the special EPROM chip. Of course, all this applies to computers operating DOS. With the advent of Microsoft Windows, the display mechanism has completely changed, since it is used in graphics and not in character mode.
The encoding used in this platform also varies. In the early days of the IBM PCs (the actual IBM products and not any compatibles) in Greece, some kind of support for Greek characters had to be supplied. This was provided by means of a Greek character encoding, which came to be called Greek 437. This encoding has the following characteristics:
The labeling of this encoding as 437 is actually a misnomer, as 437 is the code set for the encoding used in the USA. IBM also tried to promote another encoding, labeled 851, which denotes the official IBM encoding for Greek characters, since it is used in other IBM systems, like PS/2, AS400 etc.
For a long time, the 437 encoding was the only one used in this platform. However, when the Greek government first started buying PCs for use in the public sector, compliance with the ELOT/ISO standard became mandatory. Thus, almost all the suppliers of IBM PCs and their compatibles were obliged to provide whichever of the two encodings was desired by their clients.
The advent of version 3.1 of Microsoft Windows, nonetheless, marked a significant change. Before its introduction, there was more than one company providing Greek character sets (fonts) for Microsoft Windows 3.0. Regrettably, they had different encodings, including both ELOT/ISO and 437. In Microsoft Windows version 3.1, the only company providing such support is the one which had already used the ELOT/ISO encoding for its Windows 3.0 products. Unfortunately, in its Windows 3.1 version, the company chose to modify the encoding, thus rendering it similar to, but no longer compliant with the ELOT standard. It should be noted that its documentation mentions greater portability as the main reason for these modifications. All later versions of this software, including the first editions of Microsoft Windows NT and Windows 95, follow this same non-standard encoding.
The latest versions of Microsoft Windows 95, Windows 98 and Windows NT use the encoding defined in the standard ISO 10646 (also known as Unicode). However, this change is a radical one, since in this encoding characters are 16 bits wide, and not all pieces of software can operate correctly in this environment.
There are many keyboard drivers for the DOS platform and almost each one of them uses a different key combination to toggle between Greek and Latin characters. Among the most often encountered are the Alt-Enter, Shift-Control-F1/Shift-Control-F2, Shift-Enter and Alt-Space. The driver is a small Terminate-and-Stay-Resident (TSR) program, which becomes operative during machine startup time. In the case of Microsoft Windows, the toggling used to be carried out by pressing Control-Alt-Space, while the newer versions use the combination Alt-Shift or Control-Shift.
Needless to say, there is a variety of other computing systems used in Greece and almost all of them are capable (in one way or another) of dealing with Greek characters. Since it would be beyond the scope of this paper to discuss them all, only a couple will be mentioned briefly.
This was an attempt to summarize the current state of affairs in the handling of Greek characters for computerized systems operating in Greece. It is hoped that it has at least described the basic problems that must be faced in the immediate future, so that a complete and per- manent solution may be developed.